Spatial data processing capabilities for processing a wide range of spatial big data streams and types.
Spatial data integration capabilities for integrating location-based social media data with authoritative geospatial data sources.
Spatial data presentation capabilities for interactively visualizing complex spatial relations and uncertainties associated with geospatial big data.
Data retrieval and storage capabilities for efficient and scalable storage of geospatial big data.
GeoBalance: Workload-aware Management of Spatiotemporal Data
GeoBalance is the adaptive workload-aware partitioning of spatiotemporal data that considers both data and query workload. This system addresses possible workload skew due to the existence of hotspots, time-varying skew, and load spikes. It is optimized for high velocity and multi-user write-intensive geospatial applications. An evolutionary algorithm was developed for GeoBalance to modify partitions in the presence of imbalance. GeoBalance employs rolling migration of partitions to avoid disrupting other services when partitions are changing.
TopoLens
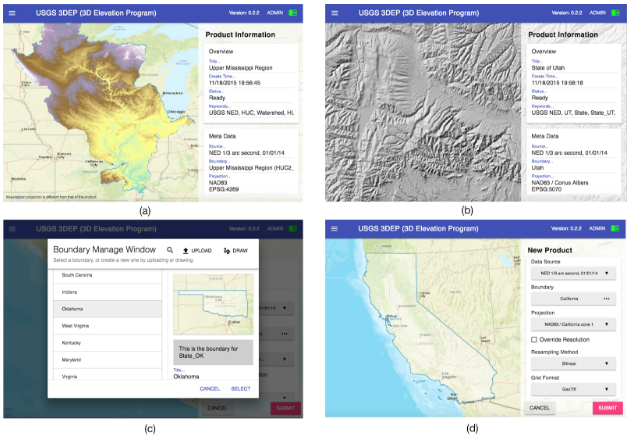
Prototyped a cyberGIS-based application for spatial big data synthesis and sharing by leveraging heterogeneous cyberinfrastructure with both cloud and HPC resources
Employed modern microservices architecture
Lowered barriers to accessing, processing, analyzing, and visualizing large raster datasets
Data from 18 hydrological regions (Hydrological Unit Code level 2) and 48 conterminousstates available
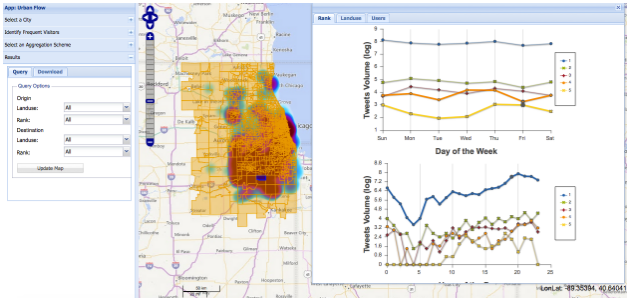
UrbanFlow
Synthesized geospatial big data from social media with authoritative land use data
Investigated population dynamics and land use changes based on the synthesized data
Implemented a cyberGIS workflow using Apache Hadoop to process large streaming data from Twitter (e.g. 965 million geo-tagged tweets in 2014)
Developed a novel distributed point-in-polygon algorithm suitable for large vector datasets
Geospatial Operation Management
Data preparation and handling operations can be used broadly and are be crucial for data sharing and synthesis. To enable these operations we will develop a capability to allow users to be able to register and publish operations that are relevant to specific types of data in a form that will enable them to be published and easily integrated by others into their workflow.